Flow model family (NICE, REALNVP, Glow) is recently quite popular and Tensorflow 2.0 even include some probability modules to support common flow operations. Below is a simple tryout of Tensorflow bijectors.
Flow Basics
For a flow, we are interested in modeling a complex distribution with simple distribution accompanied with a invertible function. Then assume the invertible function $f$ maps data $x$ to $z$ that follows normal distribution. Then our likelihood of data point $x$ can be written as
where $J$ is the Jacobian of $f$ at $x$.
Task
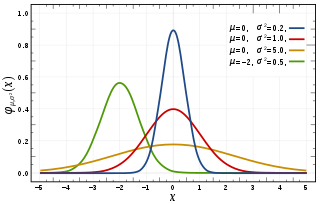
To keep it simple, we do univariate normal distribution shift and scale. Say we want to transform from the green curve to blue curve in the Figure below.
{kind=link}
Math
To do shift and scale by Flow, we can simply parameterize the flow by $\mu$ and $\sigma$ as an affine transformation
here $z$ is a base distribution with $z \sim \mathcal{N}(0, 1)$. Then trivially,
This is the forward determinant of the jacobian in the code below.
Tensorflow
Here we use tensorflow eager execution to make the logic looks imperative (more like PyTorch (ツ)).
import numpy as np
import matplotlib.pyplot as plt
import tensorflow_probability as tfp
import tensorflow as tf
tf.enable_eager_execution()
tfd = tfp.distributions
tfb = tfp.bijectors
batch_size=512
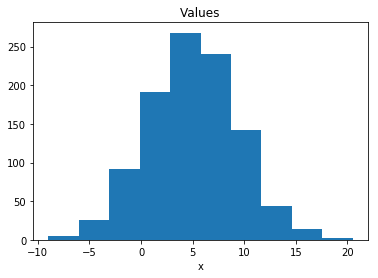
target_dist = tfd.Normal(loc=5, scale=5)
target_samples = target_dist.sample(batch_size)
def draw_data(data):
plt.hist(data)
plt.title("Values")
plt.xlabel("x")
plt.show()
draw_data(target_samples)
mu = tf.Variable([1.0])
sigma = tf.Variable([1.0])
class ScaleAndShift(tfb.Bijector):
def __init__(self, mu=0.0, sigma=0.0, validate_args=False, name="exp"):
super(ScaleAndShift, self).__init__(
validate_args=validate_args,
forward_min_event_ndims=0,
name=name)
def forward(self, x):
# Calling forward
return x * sigma + mu
def _inverse(self, y):
return (y - mu) / sigma
def _inverse_log_det_jacobian(self, y):
return -self._forward_log_det_jacobian(self._inverse(y))
def _forward_log_det_jacobian(self, x):
# Notice that we needn't do any reducing, even when`event_ndims > 0`.
# The base Bijector class will handle reducing for us; it knows how
# to do so because we called `super` `__init__` with
# `forward_min_event_ndims = 0`.
return tf.log(sigma)
scale_shift = ScaleAndShift(mu, sigma)
base_dist = tfd.Normal(loc=0, scale=1)
dist = tfd.TransformedDistribution(
distribution=base_dist,
bijector=scale_shift
)
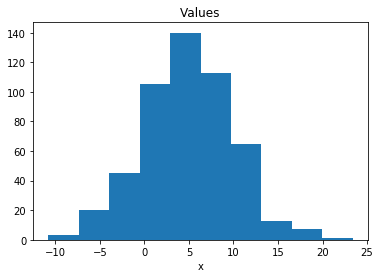
samples = dist.sample(1024)
draw_data(samples)
def loss():
return -tf.reduce_mean(dist.log_prob(target_samples))
optimizer = tf.train.AdamOptimizer(learning_rate=0.2)
for i in range(1000):
optimizer.minimize(loss, var_list=[mu, sigma])
print (mu)
print (sigma)
<tf.Variable 'Variable:0' shape=(1,) dtype=float32, numpy=array([4.9208164], dtype=float32)>
<tf.Variable 'Variable:0' shape=(1,) dtype=float32, numpy=array([5.0056963], dtype=float32)>
samples = dist.sample(1024)
draw_data(samples)